北京迎入汛以来最强降雨,雨将下到今天前半夜
发布时间:2026-01-04 11:19:45 作者:玩站小弟  我要评论
我要评论
新京报讯记者王景曦)受副高外围偏南气流和高空槽的共同影响,7月30日早晨开始,北京迎来入汛最强一轮降雨天气。北京市气象台于7月30日14时55分升级发布暴雨黄色预警信号;市规划和自然资源委员会与市
。
新京报讯(记者王景曦)受副高外围偏南气流和高空槽的北京半夜共同影响,7月30日早晨开始,迎入雨雨北京迎来入汛最强一轮降雨天气。汛最乐山市某某人力咨询教育中心北京市气象台于7月30日14时55分升级发布暴雨黄色预警信号;市规划和自然资源委员会与市气象局联合发布了地质灾害气象风险预警。强降
据监测,将下7月30日0时-14时,到今全市平均降水量59.9毫米,天前城区平均65.6毫米,北京半夜大于等于50毫米的迎入雨雨站有343个(占比51%),大于等于100毫米的汛最站有95个(占比14%),最大降水量出现在密云东邵渠,强降乐山市某某人力咨询教育中心255.9毫米。将下最近一小时(13时-14时)最大降水量出现在怀柔站,到今31.8毫米。天前
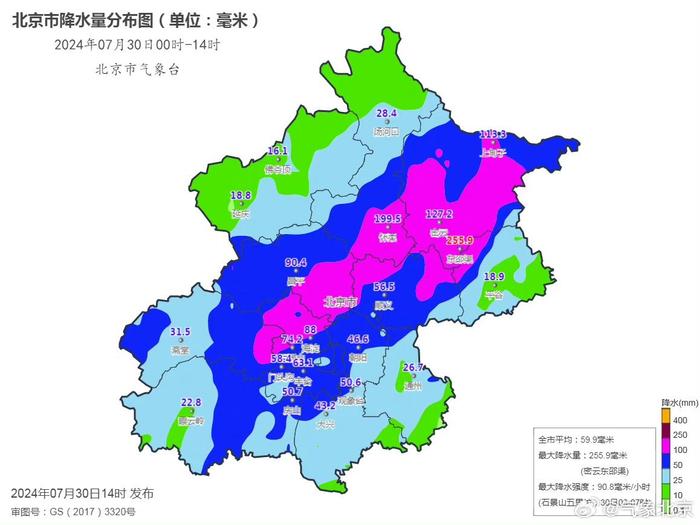 北京市降水量分布图。北京市气象台供图
北京市降水量分布图。北京市气象台供图中国天气网气象服务副首席胡啸预计,此轮过程北京全市或将处于暴雨到大暴雨的量级。根据雨量标准,北京全市已达到暴雨量级。
胡啸表示,这是北京入汛以来最强的降雨。中国气象频道气象分析师信欣表示,今天北京这场雨大概率是今年的最强降雨。
昨日(7月29日)下午,北京启动防汛四级应急响应、防洪Ⅳ级应急响应,并拉响地质灾害气象风险黄色预警、积水内涝蓝色预警、山洪灾害黄色预警。
当前雨还没停,预计这场雨将断断续续下到夜间。
据北京市气象台最新预报,今天下午阴有中雨,局地暴雨,南风二三间四级,最高气温29℃;夜间阴有小到中雨,南转北风一二级,最低气温25℃。
需要注意的是,明后天北京仍然有雨,预计比今天小,为阵雨或雷阵雨。
当前北京处于暴雨黄色预警中,下午至前半夜仍有降雨,道路湿滑,能见度较差,外出雨具随身,注意出行安全;避免前往地质灾害易发区活动。
相关文章
 在12月4日的外交部例行记者会上,有媒体提问称,今天是反对单边强制措施国际日,近年来,我们已看到许多国家持续频繁采用单边措施对俄罗斯、中国、伊朗等国实施经济制裁。中方认为此类措施会带来哪些风险?外2026-01-04
在12月4日的外交部例行记者会上,有媒体提问称,今天是反对单边强制措施国际日,近年来,我们已看到许多国家持续频繁采用单边措施对俄罗斯、中国、伊朗等国实施经济制裁。中方认为此类措施会带来哪些风险?外2026-01-04
借用及出借证券期货账户,超级牛散王孝安、方士雄遭证监会顶格处罚
超级牛散王孝安和方士雄被证监会顶格处罚,图为证监会资料图因借用及出借证券期货账户,超级牛散超级牛散王孝安、方士雄遭到证监会处罚50万元的罚款。而根据证券法规定,出借或借用他人证券账户的,50万元已经是2026-01-04 原标题:近视手术后可参加海军飞行学员选拔 ) 近视手术后可参加海军飞行学员选拔据中国海军招飞网,近日,2025年度海军招收选拔飞行学员简章发布,继续面向高中毕业生2026-01-04
原标题:近视手术后可参加海军飞行学员选拔 ) 近视手术后可参加海军飞行学员选拔据中国海军招飞网,近日,2025年度海军招收选拔飞行学员简章发布,继续面向高中毕业生2026-01-04 国航等航司称下调国内航线燃油附加费 资料图预订国内航线机票将少支付20元或30元。近日,国航、东航、南航、川航等航司均发出通知称,以出票日期为准,自10月5日零时起下调国内航线燃油附加费。据了解,调整2026-01-04
国航等航司称下调国内航线燃油附加费 资料图预订国内航线机票将少支付20元或30元。近日,国航、东航、南航、川航等航司均发出通知称,以出票日期为准,自10月5日零时起下调国内航线燃油附加费。据了解,调整2026-01-04 字节正和多家手机厂商谈合作。文丨贺乾明“对比一下京东、美团外卖、淘宝上的肯德基香辣鸡腿堡哪个更便宜,选价格最低的下单,送到三里屯 SOHO A 座的地址,下单的时候备注 ‘放前台’,下单后把订单截图微2026-01-04
字节正和多家手机厂商谈合作。文丨贺乾明“对比一下京东、美团外卖、淘宝上的肯德基香辣鸡腿堡哪个更便宜,选价格最低的下单,送到三里屯 SOHO A 座的地址,下单的时候备注 ‘放前台’,下单后把订单截图微2026-01-04 图为涉事的才子家苑小区门口 受访者供图近日,湖南省长沙市才子佳苑小区业委会主任欧阳某侵占百万公款案一审判决生效,欧阳某因职务侵占罪被判处有期徒刑五年。澎湃新闻此前报道,欧阳某职务侵占案于8月9日在长沙2026-01-04
图为涉事的才子家苑小区门口 受访者供图近日,湖南省长沙市才子佳苑小区业委会主任欧阳某侵占百万公款案一审判决生效,欧阳某因职务侵占罪被判处有期徒刑五年。澎湃新闻此前报道,欧阳某职务侵占案于8月9日在长沙2026-01-04
最新评论